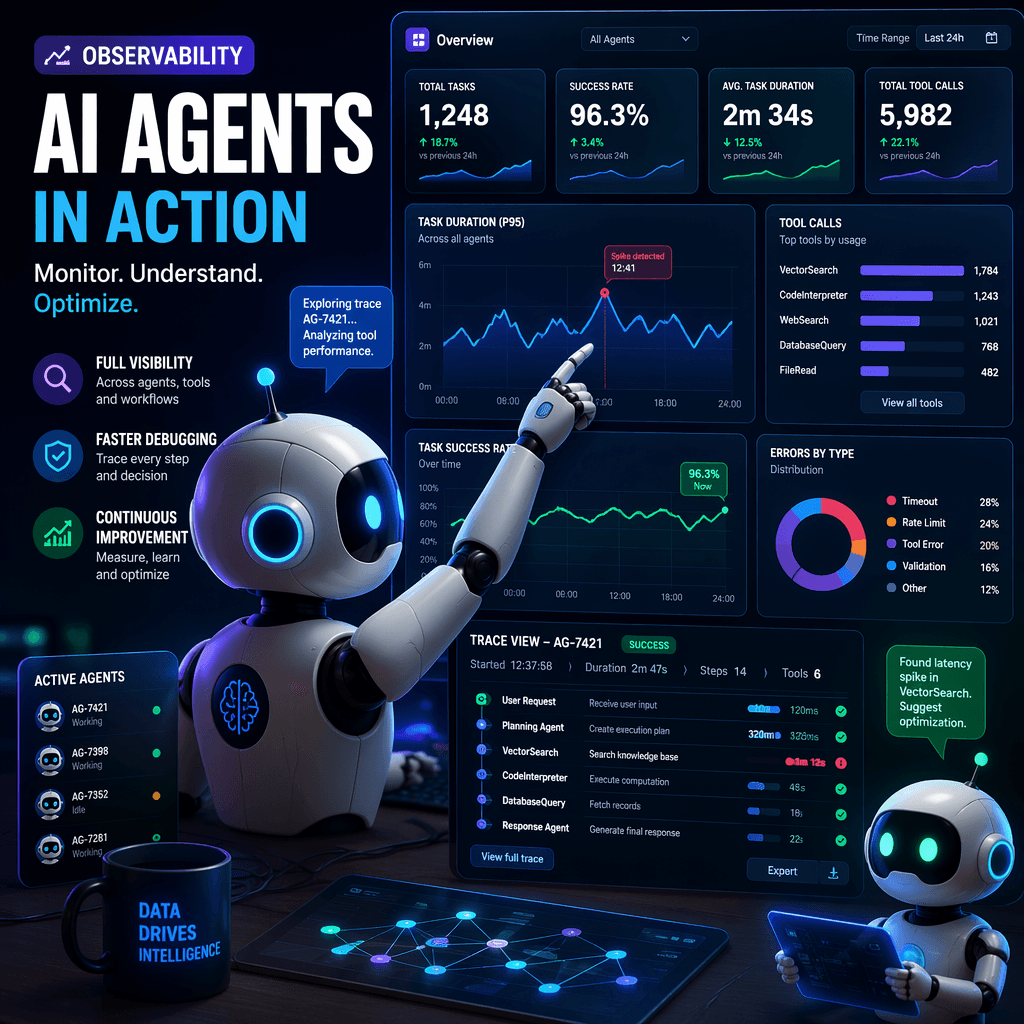
AI agents are transforming the landscape of artificial intelligence, enabling autonomous decision-making, tool invocation, and multi-step workflows. However, their complexity introduces unique challenges in observability, debugging, and monitoring. Engineers and operators need new frameworks and tools to trace agentic systems effectively in production environments.
Why Traditional Observability Fails for AI Agents
Traditional observability methods, such as metrics, logs, and traces, are designed for deterministic software systems where the same input consistently produces the same output. AI agents, however, are non-deterministic, autonomous, and context-dependent, making traditional debugging approaches insufficient. For example, when an agent fails or behaves unexpectedly, engineers need to trace its decision-making process, including the models used, prompts generated, tools invoked, and retrieved context.

Key Takeaways
- AI agents are non-deterministic and require observability frameworks tailored to their unique workflows.
- Traditional debugging methods cannot answer critical questions about agent decisions and failures.
- Observability gaps can lead to production bottlenecks and unresolved errors in agent systems.
Without proper observability, debugging agent failures is nearly impossible.
OpenTelemetry Semantic Conventions for AI Agents
OpenTelemetry has introduced semantic conventions specifically designed for AI agents, enabling standardized instrumentation and tracing. These conventions define key primitives such as agents, tasks, steps, and tools, allowing engineers to capture detailed telemetry data for every stage of an agent's workflow. For example, attributes like 'agent.name,' 'task.type,' and 'step.tool.name' provide granular insights into agent operations.
Builder note
Adopting OpenTelemetry's semantic conventions early can streamline debugging and monitoring workflows for production-grade AI agents.

Source Card
AI Agent Observability 2025: Trace & Monitor Agentic SystemsThis source highlights the evolution of observability frameworks for AI agents and provides practical guidance for implementing OpenTelemetry in production systems.
iterathon.tech
| Signal | Why it matters |
|---|---|
| Agent name | Identifies the specific agent responsible for a task. |
| Task type | Categorizes the type of work being executed. |
| Step index | Tracks the sequence of actions within a task. |
| Tool name | Indicates which external capability was invoked. |
Building a Production Observability Stack
A robust observability stack for AI agents includes tracing, metrics, and distributed monitoring. Engineers can use OpenTelemetry's SDKs to configure tracing providers, span processors, and metric exporters. For example, tracing spans can capture task durations, tool call counts, and LLM token usage, providing actionable insights into agent performance and resource consumption.
- Instrument agent frameworks with OpenTelemetry SDKs.
- Define semantic attributes for tasks, steps, and tools.
- Configure distributed tracing for multi-agent systems.
- Monitor metrics such as task duration and tool call frequency.
Distributed Tracing for Multi-Agent Systems
In scenarios where multiple agents collaborate, distributed tracing becomes essential to track interactions across systems. Engineers can propagate trace context between agents to ensure seamless observability. For example, a multi-agent orchestrator can use OpenTelemetry's TraceContextTextMapPropagator to link spans across collaborative workflows.
- Trace context propagation ensures end-to-end visibility.
- Collaborative workflows require synchronized observability.
- Distributed tracing helps identify bottlenecks in multi-agent systems.
Adoption Risks and Tradeoffs
While implementing observability frameworks for AI agents offers significant benefits, it also introduces complexity and overhead. Engineers must balance the granularity of telemetry data with system performance and storage costs. Additionally, adopting new conventions like OpenTelemetry requires training and alignment across teams.
- https://iterathon.tech/blog/ai-agent-observability-production-2025
Builder implications
For teams evaluating Mastering AI Agent Observability: Engineering Production-Grade Systems, the useful question is not whether the announcement sounds important. The useful question is whether it changes how an agent system is built, tested, operated, or bought. The source from iterathon.tech gives builders a concrete signal to inspect: AI Agent Observability 2025: Trace & Monitor Agentic Systems. That signal should be mapped against the parts of an agent stack that usually become fragile first, including tool contracts, long-running state, evaluation coverage, cost visibility, failure recovery, and the handoff between prototype code and production operations.
Production lens
Treat this as a systems decision, not a headline decision. A builder should ask how the change affects the agent loop, what needs to be measured, which failure modes become easier to catch, and whether the team can explain the behavior to a customer or operator when something goes wrong. If the answer is vague, the technology may still be useful, but it is not yet a production advantage.
Adoption checklist
- Identify the workflow where AI observability, OpenTelemetry, agent debugging, distributed tracing already creates measurable pain, such as slow triage, brittle handoffs, unclear ownership, or poor observability.
- Write down the current baseline before changing the stack: latency, cost per run, recovery rate, review time, and the percentage of tasks that need human correction.
- Prototype against a real internal workflow instead of a demo task. The workflow should include imperfect inputs, missing context, tool failures, and at least one approval step.
- Add traces, event logs, and evaluation checkpoints before expanding usage. A new framework or model is hard to judge when the team cannot see where the agent made its decision.
- Keep rollback boring. The first version should let an operator pause automation, inspect the last decision, and return control to a human without losing state.
- Review the source again after testing. The source-backed claim should line up with observed behavior in your own environment, not just with launch copy or release notes.
| Area | Question | Practical test |
|---|---|---|
| Reliability | Does the agent fail in a way operators can understand? | Run the same task with missing data, stale data, and a tool timeout. |
| Observability | Can the team reconstruct why a decision happened? | Inspect traces for inputs, tool calls, model outputs, approvals, and final state. |
| Cost | Does value scale faster than usage cost? | Compare cost per successful task against the old human or scripted workflow. |
| Governance | Can sensitive actions be reviewed or blocked? | Require approval on high-impact actions and log who approved the step. |
What to watch next
The next signal to watch is whether builders start publishing implementation notes, migration stories, benchmarks, or reliability reports around this source. That secondary evidence matters because agent infrastructure often looks clean at release time and only shows its real shape once teams connect it to messy business workflows. Strong follow-on evidence would include reproducible examples, clear limits, documented failure recovery, and customer stories that describe what changed in the operating model.
Key Takeaways
- Do not treat a release as automatically production-ready because it comes from a strong source.
- Use the source as a reason to test a specific workflow, not as a reason to rewrite the entire stack.
- The best early signal is not novelty. It is whether the system becomes easier to observe, recover, and improve.