AI agents are rapidly evolving from simple question-answering systems to autonomous entities capable of perceiving environments, planning steps, executing actions, and self-reflecting. This transformation has unlocked new possibilities for automating complex workflows, but it also introduces significant engineering challenges. Choosing the right framework is critical for building reliable, scalable, and efficient AI agents.
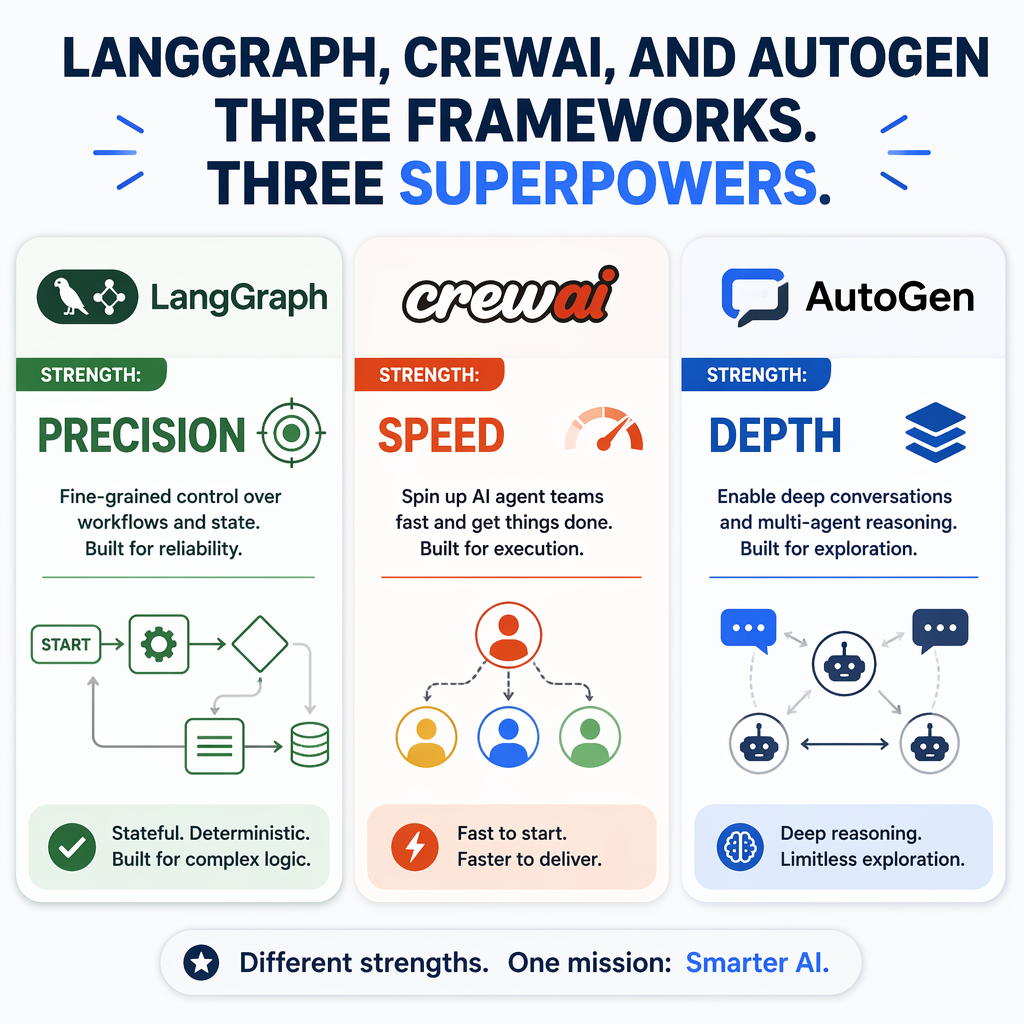
LangGraph: Precision Through State Graphs
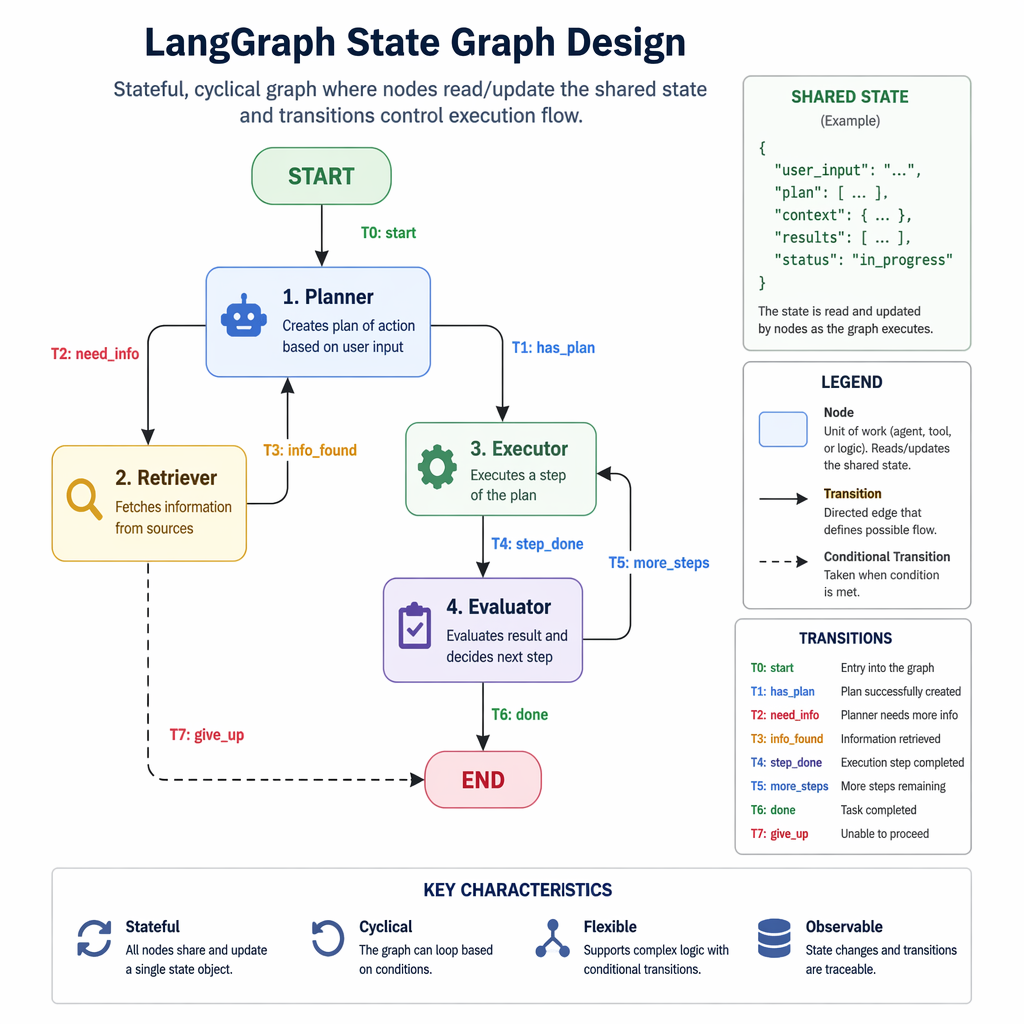
LangGraph is built around directed graph state machines, offering granular control over execution flows. This framework excels in scenarios requiring deterministic behavior, such as enterprise-grade applications where compliance and reliability are paramount. Engineers can define explicit states and transitions, ensuring predictable outcomes even in complex workflows. However, this precision comes at the cost of flexibility, as LangGraph requires detailed upfront design and is less suited for dynamic or exploratory tasks.
CrewAI: Speed Through Role-Based Collaboration
CrewAI focuses on role-based agent collaboration, enabling rapid prototyping and deployment. Each agent is assigned a specific role, such as researcher, analyst, or coordinator, and tasks are delegated accordingly. This framework is ideal for teams looking to quickly implement multi-agent systems without extensive customization. However, the tradeoff is reduced flexibility in task execution, as CrewAI's predefined roles may not align perfectly with unique use cases.
AutoGen: Depth Through Multi-Agent Negotiation
AutoGen, now in its AG2 iteration, employs a conversation-driven architecture where agents negotiate and collaborate to achieve goals. This framework shines in scenarios requiring deep reasoning and dynamic decision-making, such as research or strategy development. While AutoGen offers unparalleled depth, its steep learning curve and debugging complexity make it challenging for teams without prior experience in multi-agent systems.
Key Takeaways
- LangGraph is best for deterministic workflows requiring high reliability.
- CrewAI enables rapid development but sacrifices flexibility.
- AutoGen excels in dynamic, negotiation-heavy tasks but has a steep learning curve.

"The choice of framework depends on your application's complexity, team expertise, and deployment requirements."
Builder note
When selecting a framework, consider the tradeoffs between control, speed, and adaptability. LangGraph suits high-stakes environments, CrewAI is ideal for quick iterations, and AutoGen is best for dynamic collaboration.
Source Card
LangGraph vs CrewAI vs AutoGen: AI Agent Framework Comparison [2026]This comparison highlights the strengths and weaknesses of leading AI agent frameworks, offering practical insights for engineers and operators.
meta-intelligence.tech
| Signal | Why it matters |
|---|---|
| LangGraph's state graphs | Provides deterministic control for production-grade applications. |
| CrewAI's role-based design | Enables rapid prototyping and deployment. |
| AutoGen's multi-agent negotiation | Supports complex, dynamic workflows requiring deep reasoning. |
- Define your application's requirements: deterministic control, rapid iteration, or dynamic collaboration.
- Evaluate your team's expertise in handling complex debugging or state design.
- Consider scalability and long-term maintenance when choosing a framework.
- LangGraph requires upfront design for state transitions.
- CrewAI simplifies multi-agent collaboration but limits customization.
- AutoGen demands expertise in debugging and negotiation logic.
- LangGraph vs CrewAI vs AutoGen: AI Agent Framework Comparison [2026] - meta-intelligence.tech
Implementation Guidance
For LangGraph, start by defining your state machine with clear transitions and error-handling mechanisms. Use tools like Google Colab to prototype workflows and test edge cases. CrewAI users should focus on role definitions and task delegation, leveraging prebuilt templates for rapid deployment. AutoGen adopters should invest time in understanding multi-agent negotiation patterns and debugging strategies to ensure smooth collaboration.
Failure Modes and Mitigation
LangGraph's rigidity can lead to bottlenecks if workflows are not well-defined upfront. Mitigate this by iteratively refining state designs. CrewAI's role-based approach may struggle with tasks outside predefined roles; address this by customizing roles or integrating external tools. AutoGen's complexity can result in debugging challenges; reduce risks by starting with simpler negotiation scenarios and scaling gradually.
Adoption Contexts
LangGraph is ideal for industries like finance or healthcare, where compliance and reliability are critical. CrewAI suits startups and agile teams needing quick results. AutoGen fits research-intensive domains or applications requiring dynamic agent collaboration, such as academic studies or strategic planning.
Conclusion
Selecting the right AI agent framework is a balance of tradeoffs. LangGraph offers control, CrewAI delivers speed, and AutoGen provides depth. Engineers and operators must align their choice with application needs, team expertise, and long-term goals to maximize impact.
Builder implications
For teams evaluating LangGraph vs CrewAI vs AutoGen: Choosing the Right AI Agent Framework, the useful question is not whether the announcement sounds important. The useful question is whether it changes how an agent system is built, tested, operated, or bought. The source from meta-intelligence.tech gives builders a concrete signal to inspect: LangGraph vs CrewAI vs AutoGen: AI Agent Framework Comparison [2026]. That signal should be mapped against the parts of an agent stack that usually become fragile first, including tool contracts, long-running state, evaluation coverage, cost visibility, failure recovery, and the handoff between prototype code and production operations.
Production lens
Treat this as a systems decision, not a headline decision. A builder should ask how the change affects the agent loop, what needs to be measured, which failure modes become easier to catch, and whether the team can explain the behavior to a customer or operator when something goes wrong. If the answer is vague, the technology may still be useful, but it is not yet a production advantage.
Adoption checklist
- Identify the workflow where AI agent frameworks, LangGraph, CrewAI, AutoGen already creates measurable pain, such as slow triage, brittle handoffs, unclear ownership, or poor observability.
- Write down the current baseline before changing the stack: latency, cost per run, recovery rate, review time, and the percentage of tasks that need human correction.
- Prototype against a real internal workflow instead of a demo task. The workflow should include imperfect inputs, missing context, tool failures, and at least one approval step.
- Add traces, event logs, and evaluation checkpoints before expanding usage. A new framework or model is hard to judge when the team cannot see where the agent made its decision.
- Keep rollback boring. The first version should let an operator pause automation, inspect the last decision, and return control to a human without losing state.
- Review the source again after testing. The source-backed claim should line up with observed behavior in your own environment, not just with launch copy or release notes.
| Area | Question | Practical test |
|---|---|---|
| Reliability | Does the agent fail in a way operators can understand? | Run the same task with missing data, stale data, and a tool timeout. |
| Observability | Can the team reconstruct why a decision happened? | Inspect traces for inputs, tool calls, model outputs, approvals, and final state. |
| Cost | Does value scale faster than usage cost? | Compare cost per successful task against the old human or scripted workflow. |
| Governance | Can sensitive actions be reviewed or blocked? | Require approval on high-impact actions and log who approved the step. |
What to watch next
The next signal to watch is whether builders start publishing implementation notes, migration stories, benchmarks, or reliability reports around this source. That secondary evidence matters because agent infrastructure often looks clean at release time and only shows its real shape once teams connect it to messy business workflows. Strong follow-on evidence would include reproducible examples, clear limits, documented failure recovery, and customer stories that describe what changed in the operating model.
Key Takeaways
- Do not treat a release as automatically production-ready because it comes from a strong source.
- Use the source as a reason to test a specific workflow, not as a reason to rewrite the entire stack.
- The best early signal is not novelty. It is whether the system becomes easier to observe, recover, and improve.