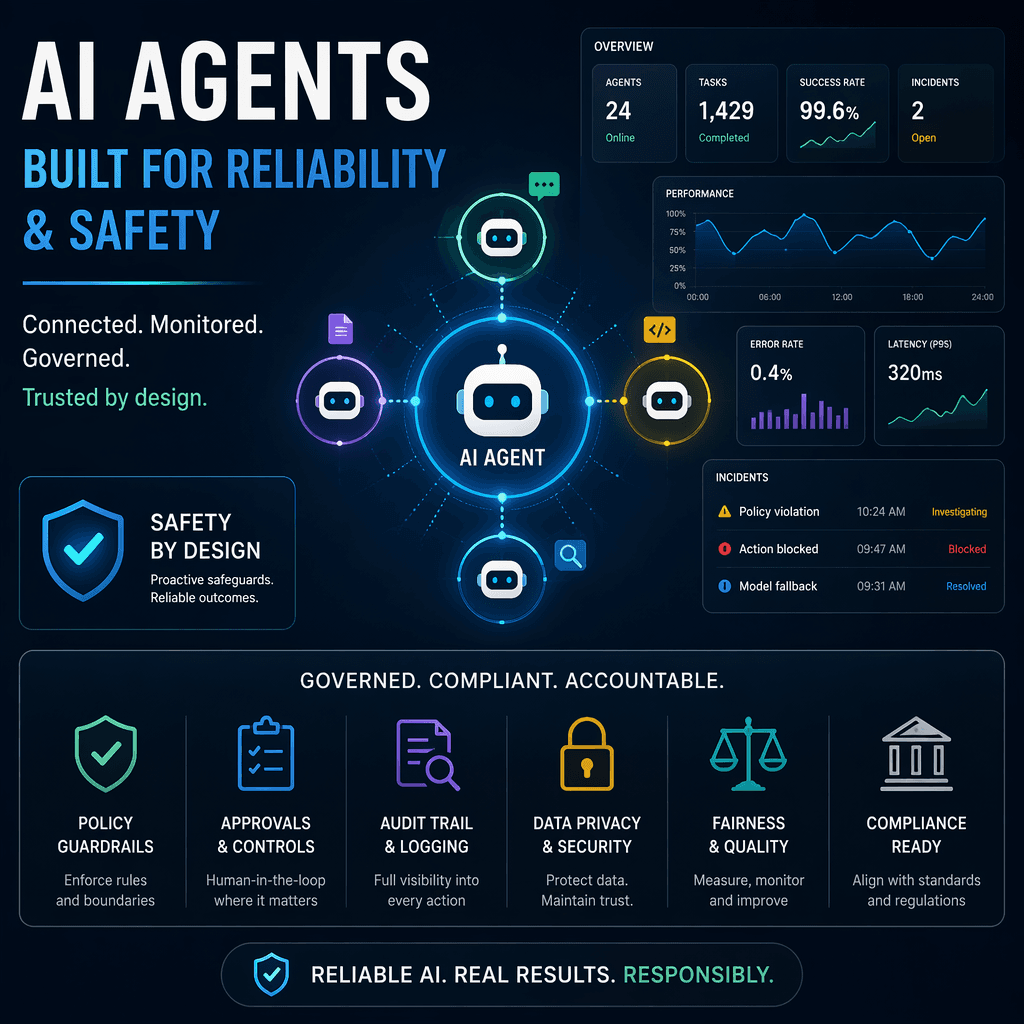
As AI agents become integral to enterprise workflows, ensuring their reliability, safety, and performance is critical. Observability provides the visibility needed to monitor, debug, and optimize these systems across their lifecycle. This article explores best practices for agent observability, offering actionable insights for engineers, founders, and operators building AI agents.
What is Agent Observability?
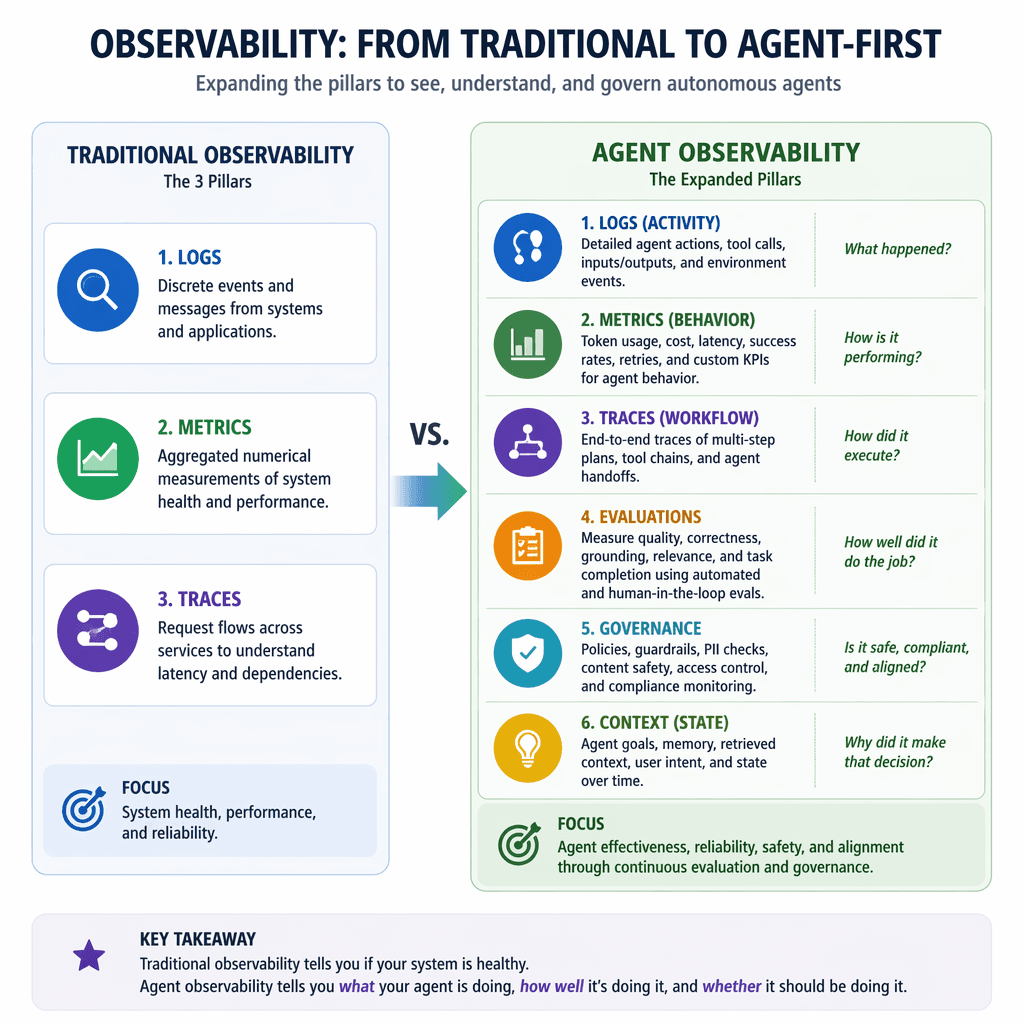
Agent observability refers to achieving deep, actionable visibility into the internal workings, decisions, and outcomes of AI agents. Unlike traditional observability focused on metrics, logs, and traces, agent observability incorporates evaluations and governance to address the unique challenges posed by non-deterministic, autonomous systems. Key components include continuous monitoring, tracing, logging, evaluation, and governance.
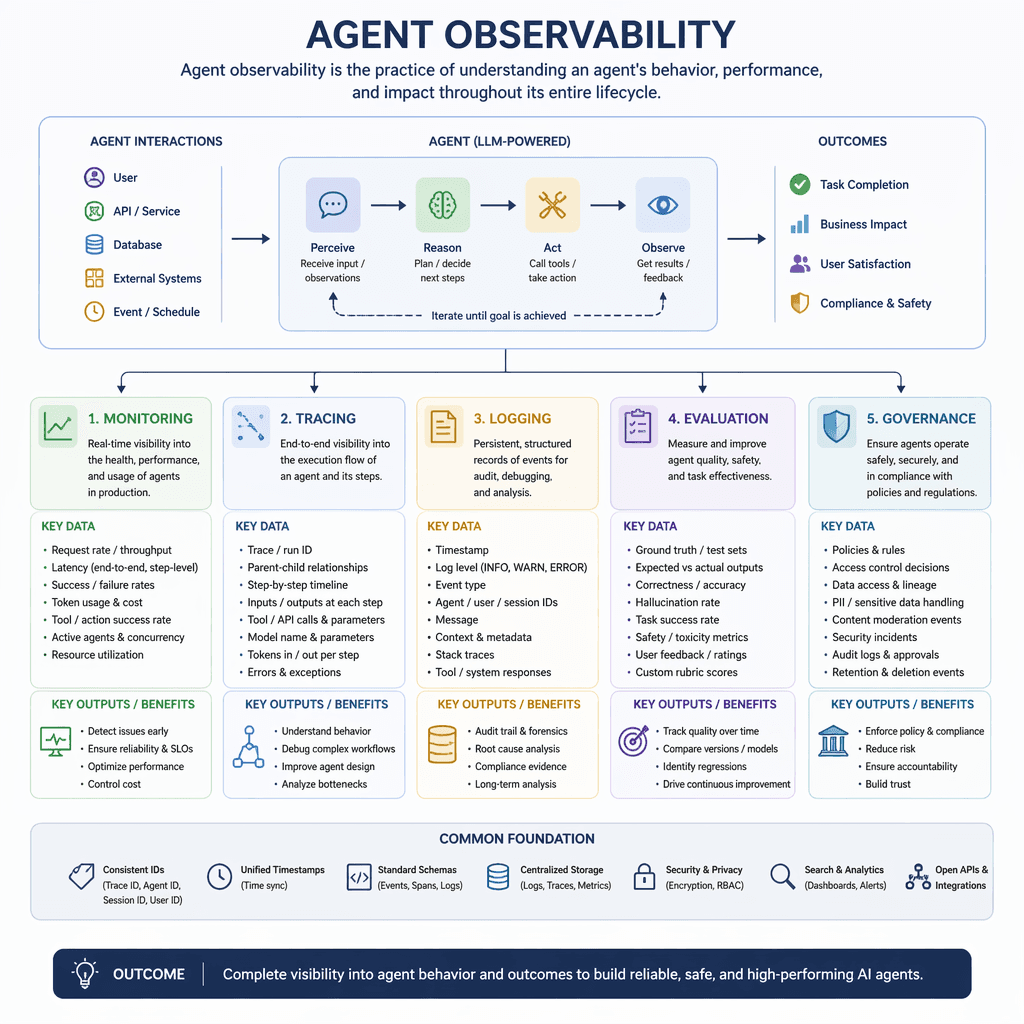
Why Traditional Observability Falls Short
Traditional observability frameworks are designed for deterministic systems, focusing on infrastructure health, latency, and throughput. However, AI agents introduce autonomy, reasoning, and dynamic decision-making, requiring expanded observability methods. Evaluations assess how well agents resolve user intent and adhere to tasks, while governance ensures ethical and compliant operation. These additions enable deeper visibility into agent behavior, supporting trustworthy AI systems at scale.
Five Best Practices for Agent Observability
- Pick the right model using benchmark-driven leaderboards: Use tools like Azure AI Foundry’s model leaderboards to compare foundation models based on quality, cost, and performance. This ensures data-driven decisions for model selection.
- Implement continuous monitoring: Track agent actions, decisions, and interactions in real time to identify anomalies and performance drift early.
- Leverage tracing for execution insights: Capture detailed execution flows to understand how agents reason through tasks, select tools, and collaborate with other systems.
- Conduct systematic evaluations: Use automated and human-in-the-loop methods to assess agent outputs for quality, safety, and compliance.
- Integrate governance frameworks: Enforce policies and standards to ensure agents operate ethically and align with regulatory requirements like the EU AI Act.
Observability empowers teams to build with confidence and scale responsibly by providing visibility into how agents behave, make decisions, and respond to real-world scenarios.
Builder Note
When implementing observability, prioritize tools that integrate seamlessly with your CI/CD pipelines. This ensures continuous evaluation and governance without disrupting development workflows.
Source Card
Agent Factory: Top 5 agent observability best practices for reliable AIThis source highlights the importance of observability in building reliable AI agents and provides actionable best practices for implementation.
Azure AI Foundry Blog
| Signal | Why it matters |
|---|---|
| Continuous monitoring | Detect anomalies and performance drift early. |
| Tracing | Understand execution flows and decision-making processes. |
| Logging | Support debugging and behavior analysis. |
| Evaluation | Ensure quality, safety, and compliance. |
| Governance | Align operations with ethical and regulatory standards. |
Adoption Challenges and Tradeoffs
Implementing agent observability comes with challenges, including increased computational overhead and the complexity of integrating new tools into existing workflows. Teams must balance the depth of observability with performance and cost considerations. For example, real-time tracing may require significant resources but is invaluable for debugging critical issues. Similarly, governance frameworks can slow deployment but are essential for regulatory compliance.
Tools for Observability in AI Agents
- Azure AI Foundry Observability: Offers end-to-end monitoring, tracing, and governance capabilities.
- Agents Playground: Enables evaluations and simulations of agent behavior.
- Azure Monitor: Provides customizable dashboards for live traffic monitoring.
- Microsoft Purview: Supports governance and compliance alignment.
- Agent Factory: Top 5 agent observability best practices for reliable AI - Azure AI Foundry Blog
- Azure AI Foundry Observability Documentation
Builder implications
For teams evaluating Agent Observability: Engineering Reliable AI Agents at Scale, the useful question is not whether the announcement sounds important. The useful question is whether it changes how an agent system is built, tested, operated, or bought. The source from azure.microsoft.com gives builders a concrete signal to inspect: Agent Factory: Top 5 agent observability best practices for reliable AI .... That signal should be mapped against the parts of an agent stack that usually become fragile first, including tool contracts, long-running state, evaluation coverage, cost visibility, failure recovery, and the handoff between prototype code and production operations.
Production lens
Treat this as a systems decision, not a headline decision. A builder should ask how the change affects the agent loop, what needs to be measured, which failure modes become easier to catch, and whether the team can explain the behavior to a customer or operator when something goes wrong. If the answer is vague, the technology may still be useful, but it is not yet a production advantage.
Adoption checklist
- Identify the workflow where AI observability, agent reliability, AI governance, Azure AI Foundry already creates measurable pain, such as slow triage, brittle handoffs, unclear ownership, or poor observability.
- Write down the current baseline before changing the stack: latency, cost per run, recovery rate, review time, and the percentage of tasks that need human correction.
- Prototype against a real internal workflow instead of a demo task. The workflow should include imperfect inputs, missing context, tool failures, and at least one approval step.
- Add traces, event logs, and evaluation checkpoints before expanding usage. A new framework or model is hard to judge when the team cannot see where the agent made its decision.
- Keep rollback boring. The first version should let an operator pause automation, inspect the last decision, and return control to a human without losing state.
- Review the source again after testing. The source-backed claim should line up with observed behavior in your own environment, not just with launch copy or release notes.
| Area | Question | Practical test |
|---|---|---|
| Reliability | Does the agent fail in a way operators can understand? | Run the same task with missing data, stale data, and a tool timeout. |
| Observability | Can the team reconstruct why a decision happened? | Inspect traces for inputs, tool calls, model outputs, approvals, and final state. |
| Cost | Does value scale faster than usage cost? | Compare cost per successful task against the old human or scripted workflow. |
| Governance | Can sensitive actions be reviewed or blocked? | Require approval on high-impact actions and log who approved the step. |
What to watch next
The next signal to watch is whether builders start publishing implementation notes, migration stories, benchmarks, or reliability reports around this source. That secondary evidence matters because agent infrastructure often looks clean at release time and only shows its real shape once teams connect it to messy business workflows. Strong follow-on evidence would include reproducible examples, clear limits, documented failure recovery, and customer stories that describe what changed in the operating model.
Key Takeaways
- Do not treat a release as automatically production-ready because it comes from a strong source.
- Use the source as a reason to test a specific workflow, not as a reason to rewrite the entire stack.
- The best early signal is not novelty. It is whether the system becomes easier to observe, recover, and improve.