
Deploying AI agents powered by large language models (LLMs) introduces unique challenges for production monitoring. Unlike traditional software, agents operate within an infinite input space, exhibit non-deterministic behavior, and require evaluation metrics rooted in conversational quality rather than system performance alone. This article explores the engineering tradeoffs, tools, and methodologies for achieving effective observability in production environments.
Why AI Agents Are Fundamentally Different
Traditional software operates within constrained input spaces, such as predefined forms, buttons, and API calls. Engineers can anticipate user behavior and design deterministic workflows with comprehensive error handling. In contrast, AI agents interact through natural language, where inputs are unbounded and user intent can be expressed in countless ways. This variability makes it impossible to predict all possible interactions before deployment.
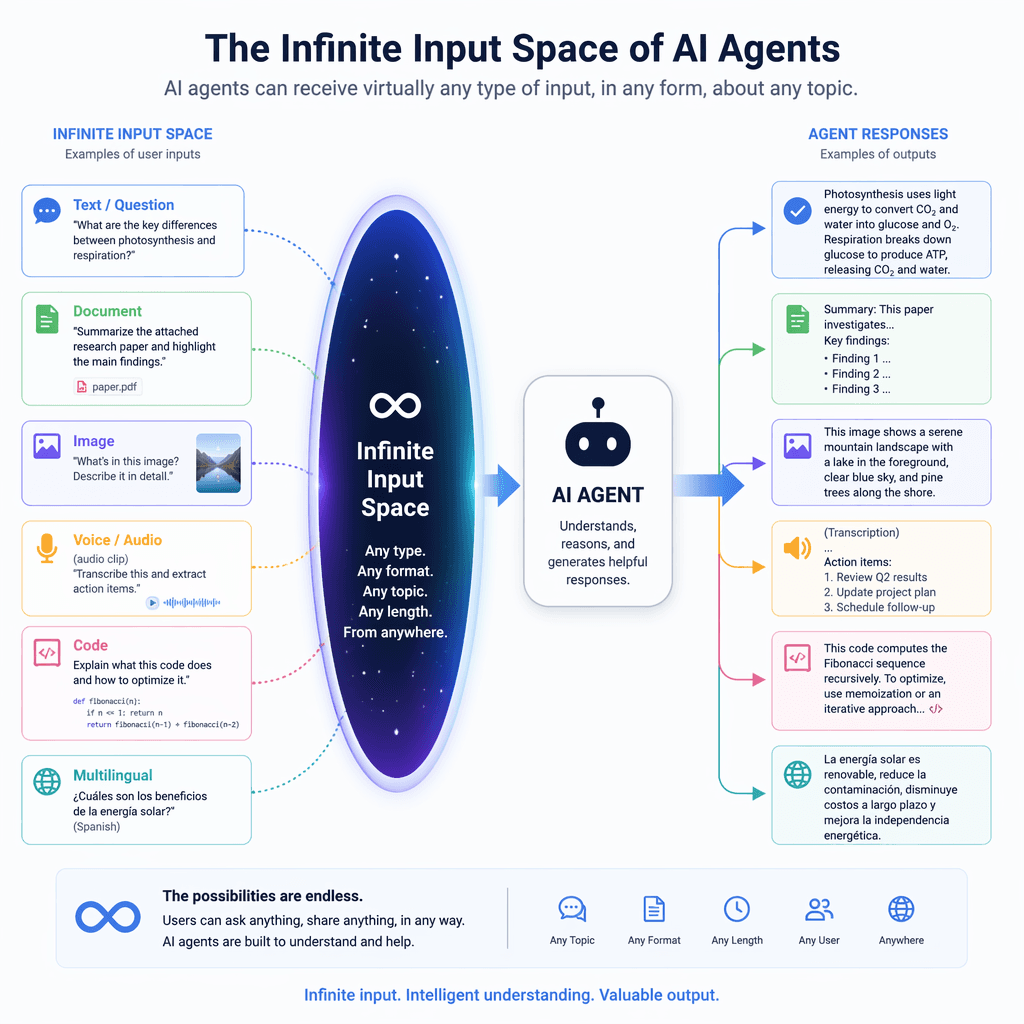
Additionally, LLMs powering these agents are sensitive to subtle changes in phrasing and context. Even small variations in input can lead to different outputs, and the same input may produce inconsistent results due to probabilistic sampling during generation. These characteristics demand a shift in monitoring strategies, focusing on conversational data and reasoning paths rather than traditional system metrics.
Key Observability Metrics for AI Agents
Effective monitoring of AI agents requires capturing signals that go beyond latency and error rates. Engineers need visibility into the following:
- Complete prompt-response pairs to understand user queries and agent replies.
- Multi-turn context to track conversations spanning multiple exchanges.
- Agent trajectories, including intermediate reasoning steps and tool calls.
- User feedback signals, such as ratings or explicit complaints.
- Cost metrics for API calls and tool usage.
These metrics enable teams to diagnose issues, evaluate agent performance, and identify areas for improvement. For example, capturing intermediate steps in an agent's reasoning process can reveal why a tool was misused or why a response failed to meet user expectations.
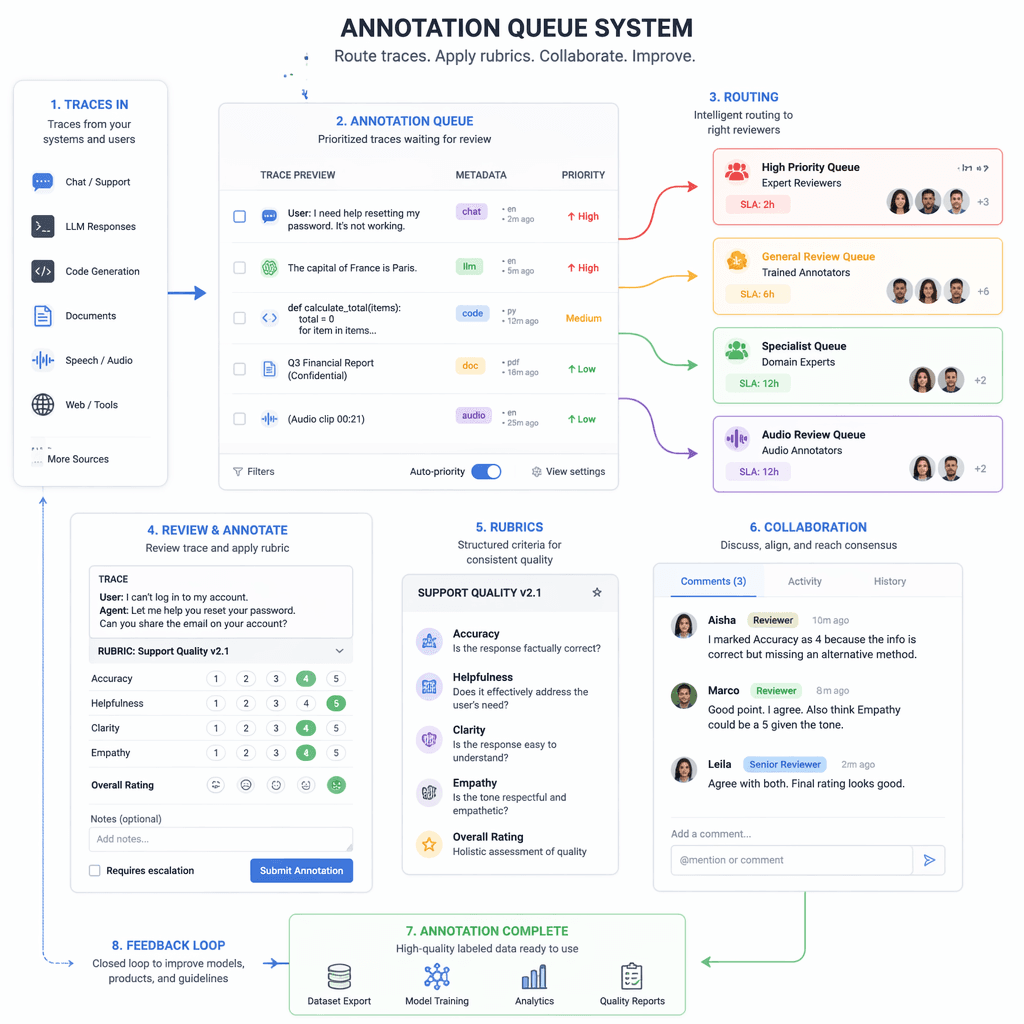
Scaling Human Evaluation in Production
Human judgment is essential for evaluating conversational quality, but manual review does not scale for high-volume production environments. Annotation queues provide a structured approach to maximize reviewer efficiency. These systems allow teams to route specific traces for review, define evaluation rubrics, and track progress collaboratively.
Key Takeaways
- AI agents require observability tools tailored to natural language interactions.
- Infinite input spaces and non-deterministic behavior make traditional monitoring insufficient.
- Annotation queues and automated evaluation pipelines help scale human judgment.
- Continuous improvement relies on production traces and structured feedback loops.
"You cannot fully predict how your agent will behave until real users start interacting with it."
Builder note
When designing observability systems for AI agents, prioritize capturing conversational data, reasoning paths, and user feedback. These signals are critical for diagnosing issues and iterating on agent performance.
Source Card
Agent Observability: How to Monitor and Evaluate LLM Agents in ProductionThis article highlights the distinct challenges of monitoring AI agents in production and provides practical guidance for engineers deploying LLM-powered systems.
LangChain
| Signal | Why it matters |
|---|---|
| Prompt-response pairs | Reveal how the agent interprets user queries and formulates replies. |
| Multi-turn context | Track the flow of conversations to ensure coherent interactions. |
| Agent trajectory | Diagnose reasoning errors and tool misuse. |
| User feedback | Identify dissatisfaction and areas for improvement. |
| Cost metrics | Monitor API usage and optimize operational expenses. |
- Capture complete conversational logs, including intermediate steps.
- Implement annotation queues for structured human review.
- Define rubrics for evaluating relevance, correctness, and tone.
- Automate feedback loops to integrate reviewed data into development.
- Monitor cost metrics to optimize API and tool usage.
Tradeoffs and Risks in Agent Observability
While observability tools for AI agents offer significant benefits, they also introduce tradeoffs and risks. Capturing detailed conversational logs can raise privacy concerns, especially in sensitive domains like healthcare or finance. Engineers must implement robust data anonymization and access controls to mitigate these risks.
Another challenge is balancing human review with automation. Over-reliance on manual evaluation can become a bottleneck, while excessive automation may overlook nuanced issues. Teams should aim for a hybrid approach, leveraging annotation queues alongside automated pipelines for scalable yet accurate evaluation.
Open Challenges and Future Directions
Despite advancements in observability tools, several challenges remain. For instance, defining universal metrics for conversational quality is difficult due to the subjective nature of human judgment. Additionally, integrating feedback from diverse user populations requires careful consideration to avoid bias.
Future research should focus on developing standardized evaluation frameworks and improving automated tools for assessing conversational quality. Collaboration between engineers, researchers, and domain experts will be essential to address these challenges effectively.
- https://www.langchain.com/blog/production-monitoring
- https://smith.langchain.com
- https://www.langchain.com/contact-sales
Builder implications
For teams evaluating Agent Observability: Engineering Insights for Monitoring LLM Agents in Production, the useful question is not whether the announcement sounds important. The useful question is whether it changes how an agent system is built, tested, operated, or bought. The source from langchain.com gives builders a concrete signal to inspect: Agent Observability: How to Monitor and Evaluate LLM Agents in Production. That signal should be mapped against the parts of an agent stack that usually become fragile first, including tool contracts, long-running state, evaluation coverage, cost visibility, failure recovery, and the handoff between prototype code and production operations.
Production lens
Treat this as a systems decision, not a headline decision. A builder should ask how the change affects the agent loop, what needs to be measured, which failure modes become easier to catch, and whether the team can explain the behavior to a customer or operator when something goes wrong. If the answer is vague, the technology may still be useful, but it is not yet a production advantage.
Adoption checklist
- Identify the workflow where AI observability, LLM agents, production monitoring, annotation queues already creates measurable pain, such as slow triage, brittle handoffs, unclear ownership, or poor observability.
- Write down the current baseline before changing the stack: latency, cost per run, recovery rate, review time, and the percentage of tasks that need human correction.
- Prototype against a real internal workflow instead of a demo task. The workflow should include imperfect inputs, missing context, tool failures, and at least one approval step.
- Add traces, event logs, and evaluation checkpoints before expanding usage. A new framework or model is hard to judge when the team cannot see where the agent made its decision.
- Keep rollback boring. The first version should let an operator pause automation, inspect the last decision, and return control to a human without losing state.
- Review the source again after testing. The source-backed claim should line up with observed behavior in your own environment, not just with launch copy or release notes.
| Area | Question | Practical test |
|---|---|---|
| Reliability | Does the agent fail in a way operators can understand? | Run the same task with missing data, stale data, and a tool timeout. |
| Observability | Can the team reconstruct why a decision happened? | Inspect traces for inputs, tool calls, model outputs, approvals, and final state. |
| Cost | Does value scale faster than usage cost? | Compare cost per successful task against the old human or scripted workflow. |
| Governance | Can sensitive actions be reviewed or blocked? | Require approval on high-impact actions and log who approved the step. |
What to watch next
The next signal to watch is whether builders start publishing implementation notes, migration stories, benchmarks, or reliability reports around this source. That secondary evidence matters because agent infrastructure often looks clean at release time and only shows its real shape once teams connect it to messy business workflows. Strong follow-on evidence would include reproducible examples, clear limits, documented failure recovery, and customer stories that describe what changed in the operating model.
Key Takeaways
- Do not treat a release as automatically production-ready because it comes from a strong source.
- Use the source as a reason to test a specific workflow, not as a reason to rewrite the entire stack.
- The best early signal is not novelty. It is whether the system becomes easier to observe, recover, and improve.