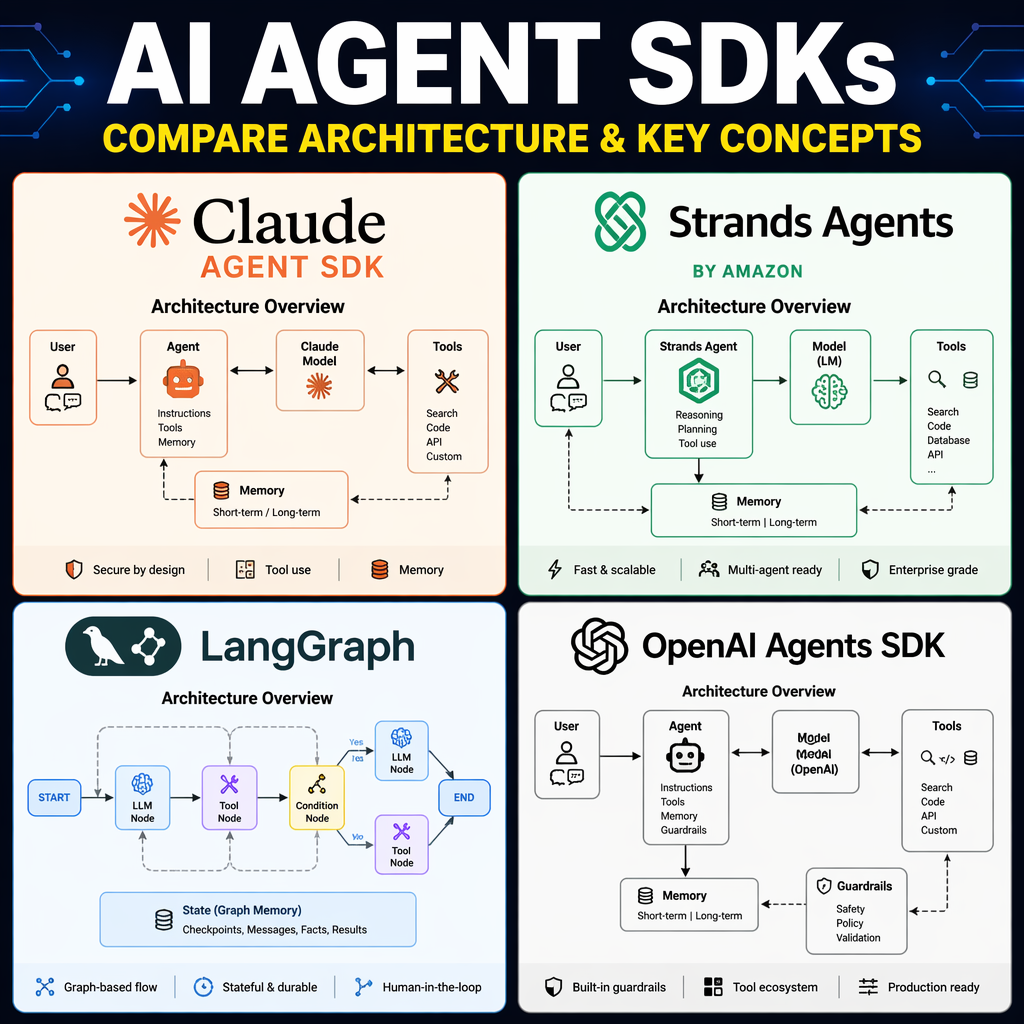
The AI agent landscape in 2026 has consolidated into four dominant frameworks: Claude Agent SDK, Strands Agents, LangGraph, and OpenAI Agents SDK. Each framework represents a distinct philosophy about agent design, state management, and developer control. For engineers, founders, and operators building AI agents, understanding these differences is critical to selecting the right tool for production workflows.
Claude Agent SDK: Stateful Runtime for Complex Tasks
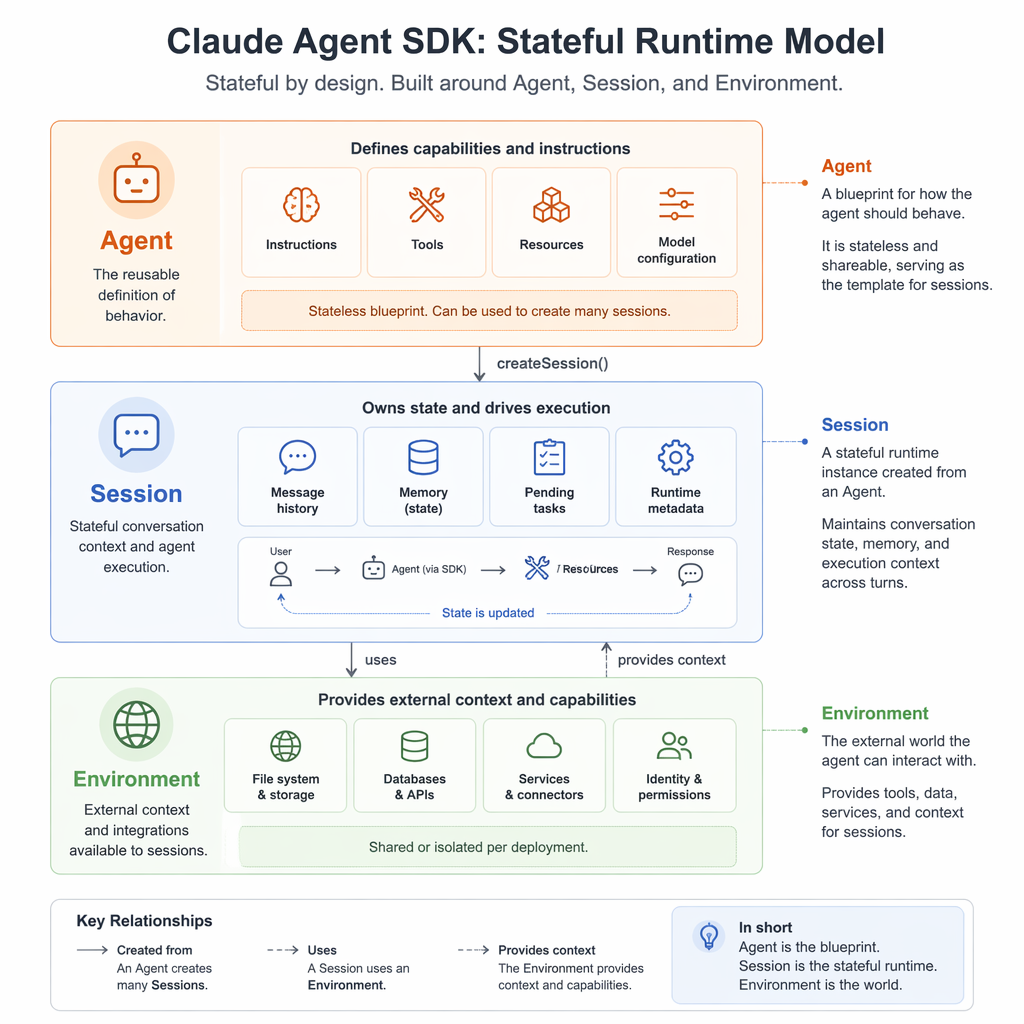
Claude Agent SDK, developed by Anthropic, treats agents as stateful, sandboxed runtimes. Its architecture revolves around four core abstractions: Agent, Environment, Session, and Events. This design enables persistent state across turns, containerized execution, and robust handling of failures. It is particularly suited for coding agents, data analysis, and workflows requiring environmental continuity.
Key Takeaways
- Claude Agent SDK excels in persistent state management and sandboxed execution.
- It is tightly coupled to Anthropic's Claude models, limiting model portability.
- Best suited for tasks requiring environmental continuity, such as coding agents or data analysis.
"Claude Agent SDK transforms agents into durable runtimes, ideal for complex workflows requiring persistent state."
Strands Agents: Minimalist Model-Driven Design
Strands Agents, open-sourced by AWS, adopts a minimalist approach where the LLM drives the agent loop. Developers define tools and provide descriptions, while the model autonomously decides tool usage and routing. This simplicity makes Strands lightweight and provider-agnostic, though it integrates deeply with AWS services like Bedrock and AgentCore.
Builder note
Strands Agents are ideal for teams seeking simplicity and provider flexibility. However, the lack of explicit state management may limit its use in workflows requiring fine-grained control.
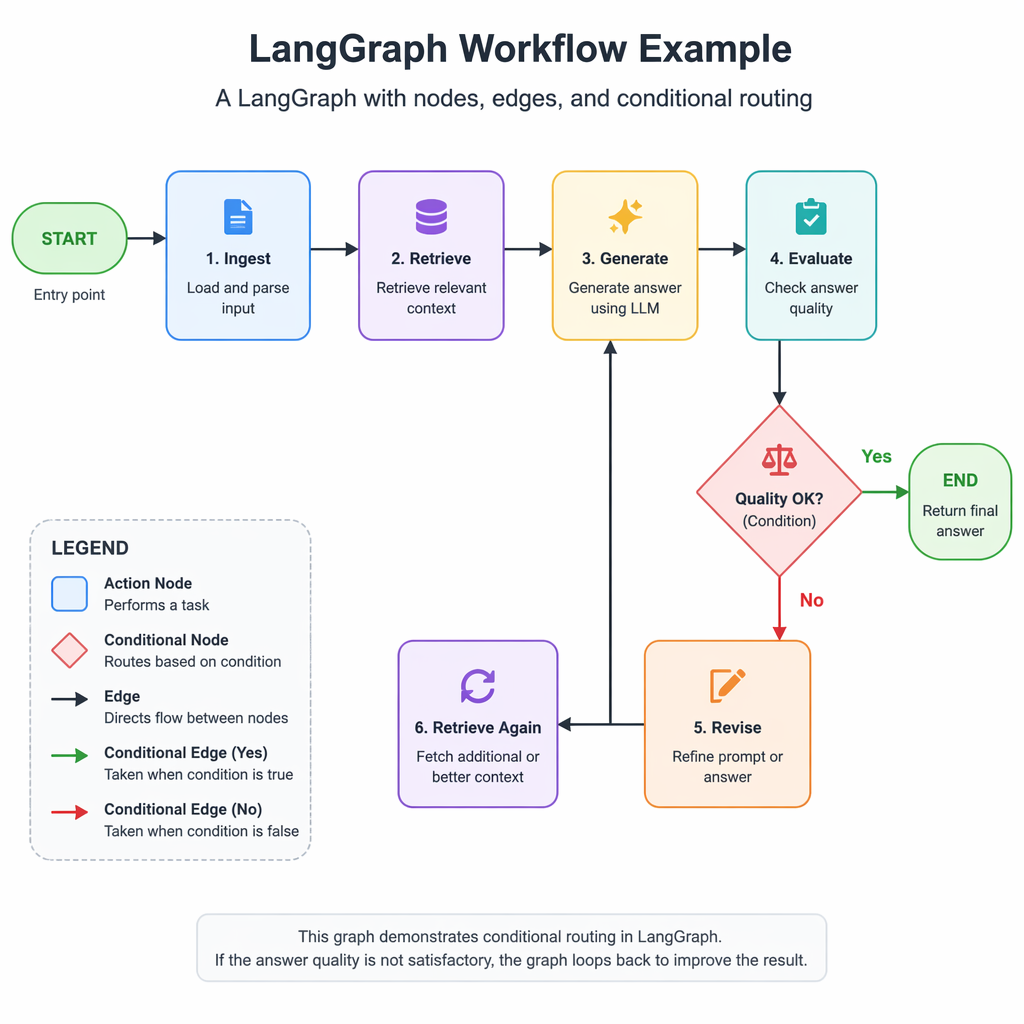
LangGraph: Directed Graphs for Explicit Control
LangGraph models agent workflows as directed graphs with explicit state. Developers define nodes, edges, and conditional routing, enabling granular control over agent orchestration. This framework is best suited for complex multi-agent systems and workflows requiring checkpointing and durable execution.
| Signal | Why it matters |
|---|---|
| Explicit graph-based orchestration | Provides granular control over agent workflows. |
| State checkpointing | Ensures durability and recovery from failures. |
| High adoption | Over 47 million monthly downloads signal strong community support. |
OpenAI Agents SDK: Handoff-Centric Specialization
OpenAI Agents SDK emphasizes handoff mechanisms, allowing agents to transfer control to specialized agents. This design is ideal for customer service workflows and tiered support systems. The recent addition of a harness system enhances long-running agent capabilities with sandbox execution and tracing.
- Define agents with clear specialization boundaries.
- Use handoffs for seamless transitions between agents.
- Leverage the harness system for safe, persistent execution.
State Management: Comparing Philosophies
State management is a critical differentiator among these frameworks. Claude Agent SDK offers persistent state within sandboxed environments, while LangGraph provides explicit state modeling through directed graphs. Strands Agents rely on the LLM for implicit state management, and OpenAI Agents SDK uses handoffs and harnesses for context preservation.
- Claude Agent SDK: Persistent state across sessions.
- LangGraph: Explicit state modeling with checkpointing.
- Strands Agents: Implicit state driven by the LLM.
- OpenAI Agents SDK: Context preservation via handoffs and harnesses.
Source Card
2026 AI Agent Framework Showdown: Claude Agent SDK vs Strands vs ...This source provides a detailed comparison of the four major AI agent frameworks, highlighting architectural differences, state management, and production readiness.
QubitTool Tech Team
Trade-offs and Adoption Guidance
Choosing the right framework depends on your workflow requirements and ecosystem preferences. Claude Agent SDK is ideal for tasks requiring persistent state and containerized execution but lacks model flexibility. Strands Agents offer simplicity and provider-agnosticism, though they may not suit workflows needing explicit state control. LangGraph provides unparalleled orchestration control but demands significant upfront design effort. OpenAI Agents SDK excels in specialized workflows with clear boundaries but may require deeper integration for complex multi-agent systems.
- https://qubittool.com/blog/ai-agent-framework-comparison-2026
- https://aws.amazon.com/blogs/opensource/strands-agents-and-the-model-driven-approach
- https://letsdatascience.com/blog/claude-agent-sdk-tutorial
- https://qubittool.com/en/blog/langgraph-vs-autogen-multi-agent-frameworks
Conclusion: Frameworks for Builders
The 2026 AI agent framework landscape offers diverse options for builders. Claude Agent SDK is best for stateful, sandboxed workflows, Strands Agents for lightweight, model-driven designs, LangGraph for explicit orchestration, and OpenAI Agents SDK for specialized handoff-centric systems. Evaluate your workflow needs, ecosystem compatibility, and long-term scalability before making a choice.
Builder implications
For teams evaluating 2026 AI Agent Framework Showdown: Engineering Insights for Builders, the useful question is not whether the announcement sounds important. The useful question is whether it changes how an agent system is built, tested, operated, or bought. The source from qubittool.com gives builders a concrete signal to inspect: 2026 AI Agent Framework Showdown: Claude Agent SDK vs Strands vs .... That signal should be mapped against the parts of an agent stack that usually become fragile first, including tool contracts, long-running state, evaluation coverage, cost visibility, failure recovery, and the handoff between prototype code and production operations.
Production lens
Treat this as a systems decision, not a headline decision. A builder should ask how the change affects the agent loop, what needs to be measured, which failure modes become easier to catch, and whether the team can explain the behavior to a customer or operator when something goes wrong. If the answer is vague, the technology may still be useful, but it is not yet a production advantage.
Adoption checklist
- Identify the workflow where AI agent frameworks, Claude Agent SDK, LangGraph, OpenAI Agents SDK already creates measurable pain, such as slow triage, brittle handoffs, unclear ownership, or poor observability.
- Write down the current baseline before changing the stack: latency, cost per run, recovery rate, review time, and the percentage of tasks that need human correction.
- Prototype against a real internal workflow instead of a demo task. The workflow should include imperfect inputs, missing context, tool failures, and at least one approval step.
- Add traces, event logs, and evaluation checkpoints before expanding usage. A new framework or model is hard to judge when the team cannot see where the agent made its decision.
- Keep rollback boring. The first version should let an operator pause automation, inspect the last decision, and return control to a human without losing state.
- Review the source again after testing. The source-backed claim should line up with observed behavior in your own environment, not just with launch copy or release notes.
| Area | Question | Practical test |
|---|---|---|
| Reliability | Does the agent fail in a way operators can understand? | Run the same task with missing data, stale data, and a tool timeout. |
| Observability | Can the team reconstruct why a decision happened? | Inspect traces for inputs, tool calls, model outputs, approvals, and final state. |
| Cost | Does value scale faster than usage cost? | Compare cost per successful task against the old human or scripted workflow. |
| Governance | Can sensitive actions be reviewed or blocked? | Require approval on high-impact actions and log who approved the step. |
What to watch next
The next signal to watch is whether builders start publishing implementation notes, migration stories, benchmarks, or reliability reports around this source. That secondary evidence matters because agent infrastructure often looks clean at release time and only shows its real shape once teams connect it to messy business workflows. Strong follow-on evidence would include reproducible examples, clear limits, documented failure recovery, and customer stories that describe what changed in the operating model.
Key Takeaways
- Do not treat a release as automatically production-ready because it comes from a strong source.
- Use the source as a reason to test a specific workflow, not as a reason to rewrite the entire stack.
- The best early signal is not novelty. It is whether the system becomes easier to observe, recover, and improve.